
VIII. |
TYPY POLE, ŘETĚZEC A ZÁZNAM |
Pole a záznamy jsou strukturované datové typy. Používají se v případech, kdy je vhodné v jediné proměnné soustředit více dílčích údajů, nějakým způsobem souvisejících. Pokud jsou všechny dílčí údaje stejného typu, je možné použít pole, v opačném případě je nutné použít záznam.
Řetězce jsou v podstatě poli znaků. Vzhledem k jistým speciálním vlastnostem, které ostatní typy polí postrádají, tvoří řetězce samostatnou třídu typů.
VIII.1. |
Typy pole |
Obecně smí být indexem hodnota libovolného ordinálního typu, jehož velikost činí maximálně 2 byty (tento požadavek souvisí se způsobem adresování prvků). Typem indexu tedy nesmí být LongInt ani interval na hostitelském typu LongInt (například interval 70000 .. 70010). Celkový počet různých hodnot typu indexu určuje počet prvků pole, neboť každé přípustné hodnotě indexu přísluší v poli právě jeden prvek.
Obrázek 35: Popis typu pole
|
|
Typ indexu i typ prvků pole je stanoven jeho popisem (obrázek 35). Typ indexu se uvádí uvnitř hranaté závorky za rezervovaným slovem array, typ prvků pak za rezervovaným slovem of. Požadavky na typ indexu byly diskutovány v předchozím odstavci, na typ prvků žádná omezení kladena nejsou.
Následující příklad uvádí popis pole jedenácti prvků. Prvky jsou indexovány čísly z intervalu 10 .. 20 (indexem prvního prvku je číslo 10, druhého 11 atd.) a jejich hodnotami jsou reálná čísla.
V deklaracích vícerozměrných polí je možné využít ekvivalence následujících druhů popisu pole:array [10 .. 20] of Real
je totéž jakoarray [index1] of array [index2] of prvek
Počet indexů — dimenze pole — není jazykem omezena, omezena je však maximální velikost každého typu na 64 KB (přesněji na 65 535 bytů). Velikost typu pole je dána součinem počtu prvků pole (počtu různých hodnot typu indexu) a velikosti prvku. Tak například níže deklarovaný typ Vektor má velikost 18 bytů (3 × 6), typ Matice 54 bytů (3 × 18), typ Pole 21 bytů (21 × 1) a typ PolePoli 13 312 bytů (256 × 26 × 2).array [index1, index2] of prvek
const Max = 10;
type Vektor = array [1..3] of Real;
Matice = array [1..3] of Vektor;
Index = -Max..Max;
Pole = array [Index] of Boolean;
PolePoli = array [Byte, 'A'..'Z'] of Integer;
Pole variabilní velikosti nejsou povolena. Počet komponent musí být deklarací jednoznačně určen již v okamžiku kompilace. Není možné deklarovat pole například takto:
var N: Byte;
R: array [1..N] of Integer;
(S úmyslem zadat aktuálně potřebnou hodnotu N až při běhu programu.) Při překladu deklarace proměnné R dojde k chybě, neboť v popisu typu interval, který je uveden jako typ indexu pole, není horní mez konstantním výrazem.
Pokud je aktuálně potřebný počet prvků pole znám až během výpočtu programu, musí být deklarovaný počet prvků roven maximálnímu počtu prvků, který pro danou úlohu připadá v úvahu. Pro konkrétní případ je pak využita pouze potřebná část deklarovaného pole.
Volba hodnoty konstanty Max je obvykle kompromisem mezi snahou o univerzálnost programu (co největší Max) a snahou o přiměřenou paměťovou náročnost programu (co nejmenší Max).const Max = 50; var R : array [1..Max] of Integer;
Typové konstanty V deklaraci typové konstanty, jejímž typem je pole, je třeba uvést její počáteční hodnotu ve tvaru konstantního pole.
Obrázek 36: Konstantní pole

|
Konstantní pole je uzavřeno v kulaté závorce a obsahuje seznam hodnot jednotlivých prvků v pořadí od prvního do posledního prvku pole. Hodnoty prvků mají tvar typových konstant.
type Pole = array [1..3, 1..2] of Char;
const A : array ['A'..'C'] of Byte
= (7, 14, 21);
B : Pole
= (('k', 'l'), ('m', 'n'), ('o', 'p'));
Přístup k prvkům Operace přístup k prvku pole je definována (pro proměnné libovolného typu pole) syntaktickým diagramem na obrázku 37. Uvedená proměnná musí být typu pole, hodnota výrazu kompatibilní vzhledem k přiřazení s typem odpovídajícího indexu a počet výrazů nesmí být větší než deklarovaný počet indexů.
Obrázek 37: Přístup k prvku pole

|
Výsledkem operace je proměnná (!) typu prvku pole, odpovídající uvedenému indexu (indexům). Přístup k prvku pole lze proto užít všude tam, kde je povolen výskyt proměnné typu prvku (například i na levé straně přiřazovacího příkazu nebo na místě skutečného, odkazem volaného parametru podprogramu).
var A: array [Byte] of Char;
B: array ['a'..'z'] of Real;
C: array [Byte, 'a'..'z'] of Boolean;
Produktem operací přístupu k prvkům výše deklarovaných polí A, B a C jsou tedy proměnné následujících vlastností:
| A [0] až A [255] | jsou prvky pole A, tedy proměnné typu Char | |
| B ['a'] až B ['z'] | jsou prvky pole B, tedy proměnné typu Real | |
| C [0] až C [255] | jsou prvky pole C, tedy proměnné typu array ['a' .. 'z'] of Boolean | |
| C [7]['a'] až C [7]['z'] | jsou prvky pole C [7], tedy proměnné typu Boolean | |
| C [7, 'a'] až C [7, 'z'] | jsou zkrácené zápisy přístupu k proměnným C [7]['a'] až C [7]['z'] |
Kontrola hodnoty indexu na jeho deklarovaný rozsah je za běhu programu prováděna pouze v případě, že byl přeložen při nastavené direktivě kompilátoru {$R+}. Překročení rozsahu indexu při přístupu k prvku pole pak vede k běhové chybě a ukončení programu. Při potlačené kontrole rozsahu může mít jeho překročení v indexu pole vážné důsledky.
var Pole : array [1..10] of Byte;
Index : Byte;
...
Index := 0;
while Index <= 10 do
begin
Inc(Index);
Pole[Index] := 0
end;
...
Například v předchozí ukázce vede překročení rozsahu indexu k nekonečnému cyklu. Program vloží pro Index = 11 nulu za poslední existující prvek pole — na paměťové místo, které přísluší proměnné Index (provede se tedy vlastně příkaz Index := 0).
Přiřazovací příkaz Pro proměnné typu pole je definován také přiřazovací příkaz. Kompatibilita vzhledem k přiřazení je pro typ pole definována tak, že na levé i pravé straně přiřazovacího příkazu musí být proměnné identických typů pole (s výjimkou polí znaků, jejichž kompatibilita i kompatibilita vzhledem k přiřazení je dána pouze stejným počtem prvků). Pro pole je tedy funkce přiřazovacího příkazu zúžena na pouhé zkopírovaní obsahu zvolené proměnné do proměnné identického typu.
var A, B : array [1..3] of Real;
C, D : array [1..3, 1..3] of Real;
E : array [1..3] of Real;
...
A := B;
C := D;
C[1] := C[2];
C[1] := D[1];
A := E; { !!! chyba !!! }
...
Zkopírování obsahu proměnné typu pole do jiné proměnné typu pole lze samozřejmě realizovat i po jednotlivých prvcích:
Ve všech přiřazovacích příkazech se nyní vyskytují pouze proměnné typu Real (nikoliv pole), takže je přípustná i druhá řádka ukázky. Kopírování po prvcích je však pomalejší a jeho zápis rozsáhlejší (ve zdrojovém textu i v cílovém kódu programu).A[1] := B[1]; A[2] := B[2]; A[3] := B[3]; A[1] := E[1]; A[2] := E[2]; A[3] := E[3];
{======================================================================}
program Mereni;
{======================================================================}
const Max = 20; { maximální počet měření }
var N, { skutečný počet měření }
K : Byte; { číslo měření }
Odpor, { výsledný odpor }
Chyba, { střední kvadratická chyba }
Soucet : Real; { pomocná proměnná pro }
{ výpočet aritmetických průměrů }
U, { naměřená napětí }
I, { naměřené proudy }
R : array [1..Max] of Real; { vypočtené odpory }
begin { program }
Writeln; { tisk titulku }
Writeln('MĚŘENÍ ELEKTRICKÉHO ODPORU');
Writeln;
repeat { zadání počtu měření }
Write('Počet měření (2 - ', Max, ') : ');
Readln(N)
until (N > 1) and (N <= Max);
Writeln;
Soucet := 0; { inicializace součtu odporů }
for K := 1 to N do { pro všechna měření }
begin
Write(K:2, '. U [V] : '); { načtení naměřených hodnot }
Readln(U[K]); { napětí }
Write('I [A] : ':12); { a proudu }
Readln(I[K]);
R[K] := U[K]/I[K]; { výpočet odporu }
Soucet := Soucet + R[K] { aktualizace součtu }
end;
Odpor := Soucet/N; { aritmetický průměr vypočtených }
{ hodnot odporu }
Soucet := 0; { inicializace součtu kvadrátů }
{ odchylek vypočtených odporů od }
{ jejich aritmetického průměru }
Writeln; { tisk tabulky měření }
Writeln('+------+------------+------------+------------+------------+');
Writeln('| č.m. | U [V] | I [A] | R [Ohm] | dR [Ohm] |');
Writeln('+------+------------+------------+------------+------------+');
for K := 1 to N do { pro všechna měření }
begin
Chyba := R[K] - Odpor; { výpočet odchylky }
Soucet := Soucet + sqr(Chyba); { aktualizace součtu }
Writeln('|', K:5, { tisk čísla měření }
' |', U[K]:11:3, { naměřeného napětí }
' |', I[K]:11:3, { naměřeného proudu }
' |', R[K]:11:3, { vypočteného odporu }
' |', Chyba:11:3, ' |') { odchylky }
end;
Writeln('+------+------------+------------+------------+------------+');
Writeln;
Chyba := Sqrt(Soucet/N/(N-1)); { výpočet střední kvadratické }
{ chyby }
Writeln('R = (', Odpor:1:3, { tisk výsledku }
'+ ', Chyba:1:3, ') Ohm');
Writeln
end. { program }
VIII.2. |
Typy řetězec |
Základními atributy řetězců jsou jejich maximální a aktuální délka (počet znaků). Maximální délka je deklarována popisem typu a nelze ji proto v průběhu programu měnit. Aktuální délka je součástí proměnné a závisí na její aktuální hodnotě.
Obrázek 38: Popis typu řetězec
|
|
Výrazem, uvedeným v popisu řetězcového typu, musí být konstantní výraz, jehož hodnotou je celé kladné číslo z intervalu <1, 255>. Má význam definice maximální délky řetězce, který ještě může být hodnotou tohoto typu, a tím určuje velikost tohoto typu. Proměnná typu string [Max] je totiž alokována na Max + 1 bytech. Úvodní byte obsahuje aktuální délku n řetězce a následujících n bytů je interpretováno jako aktuální hodnota řetězce (n znaků), hodnoty zbývajících bytů jsou nedefinované. Znaky jsou libovolné hodnoty typu Char.
Pokud v popisu typu není maximální délka uvedena, bere se implicitně 255. V takovém případě lze rezervované slovo string použít rovněž jako identifikátor typu. To má význam v některých deklaracích, které striktně vyžadují identifikátor typu, nikoliv pouze jeho popis (například typ formálních parametrů podprogramů).
Typové konstanty V deklaraci typové konstanty, jejímž typem je řetězec, je třeba uvést počáteční hodnotu konstanty ve tvaru konstantního výrazu (zpravidla jím bývá řetězcový literál).
Přiřazení hodnoty proměnné Proměnné kteréhokoliv typu řetězec lze přiřadit libovolný výraz, jehož hodnotou je znak, řetězec nebo pole znaků. Hodnota výrazu je zkonvertována na řetězec stejné maximální délky, jako má proměnná (případné nadbytečné znaky se odříznou zprava), z nějž se pak do proměnné kopíruje délkový byte a všechny platné znaky.
Přístup ke znakům řetězce Je definován stejným způsobem, jako přístup k prvkům pole — pomocí indexu. Syntaxi přístupu ke znaku řetězce popisuje diagram na obrázku 39: proměnná musí být řetězcového typu, výraz má význam indexu znaku a jeho hodnotou musí být nezáporné celé číslo.
Obrázek 39: Přístup ke znaku řetězce
|
|
Jednotlivé prvky pole — byty proměnné — jsou indexovány od nuly výše: délkový byte má index 0, byte prvního znaku 1 atd. Indexem posledního platného znaku je aktuální délka řetězce a indexem posledního znakového bytu proměnné je maximální délka řetězce. Překročení rozsahu indexu má stejné důsledky jako při přístupu k prvku pole — při aktivní kontrole rozsahu způsobí běhovou chybu, jinak je ignorováno.
Výsledkem operace přístupu ke znaku řetězce je proměnná typu Char. Jako proměnná typu Char může být takto zpřístupněn i délkový byte řetězce. Pokud tedy má být tímto způsobem měněna nebo zjišťována aktuální délka řetězce, je nutné zajistit odpovídající konverzi hodnoty typu Byte na Char nebo obráceně.
var S: string;
L: Byte;
... { hodnota S: }
S := 'abcdefgh'; { 'abcdefgh' }
L := Ord(S[0]); { 'abcdefgh' }
S[0] := Chr(L - 1); { 'abcdefg' }
S[1] := S[Ord(S[0])]; { 'gbcdefg' }
S[0] := #0; { '' }
S[3] := 'E'; { '' }
S[0] := Chr(L); { 'gbEdefgh' }
...
Řetězcové parametry podprogramů Skutečnými parametry, příslušejícími hodnotou volaným formálním parametrům libovolného řetězcového typu, mohou být výrazy typu řetězec, pole znaků nebo znak (jak stanoví kompatibilita řetězcových proměnných vůči přiřazení hodnoty). Pro odkazem volané parametry podprogramů je standardně požadována identita typů formálního a skutečného parametru. Pokud je však typ formálního parametru řetězcový (string nebo pojmenovaný řetězcový typ), lze požadavek na striktní identitu typů vypnout direktivou {$V–} kompilátoru. Skutečným parametrem pak smí být proměnná libovolného řetězcového typu.
Direktiva {$V–} resp. {$V+} se uvádí na začátku uvažovaného úseku zdrojového textu a platí až do dalšího výskytu téže direktivy s opačným znaménkem.
Nedodržení identity typu při předávání odkazem volaného řetězcového parametru je poměrně nebezpečnou akcí. Pokud je totiž velikost skutečného parametru menší než velikost formálního parametru, může dojít k přepsání obsahu paměťového úseku bezprostředně následujícího za úsekem, v němž je alokován skutečný parametr.
{======================================================================}
program VarStringsDemo;
{======================================================================}
{$V-} { vypnuta kontrola identity }
{ typů řetězcových parametrů }
type Formalni = string [10]; { typ formálního parametru }
var S : string [5]; { skutečný parametr }
Znak : Char; { první byte za skutečným }
{ parametrem }
procedure Proc (var F: Formalni);
{-------------------------------}
begin { Proc }
F := 'nazdar'
end; { Proc }
begin { program }
Znak := 'Z'; { kontrolní hodnota }
Proc(S);
WriteLn(Znak) { výpis kontrolní hodnoty }
end. { program }
Nově v Turbo Pascalu verze 7.0 byl zaveden standardní identifikátor OpenString, který může být uváděn místo typu v deklaraci formálních řetězcových parametrů podprogramů. Při volání odkazem je pak typem formálního parametru tzv. otevřený řetězec — string [X], kde X je deklarovaná maximální délka aktuálně uvedeného skutečného parametru. Skutečným parametrem může tedy být opět (jako při vypnutí kontroly identity řetězcových typů) proměnná libovolného řetězcového typu, žádné nebezpečí porušení integrity programu však nehrozí.
Prohřeškem proti syntaxi není ani uvedení identifikátoru OpenString místo typu v deklaraci hodnotou volaného formálního řetězcového parametru, typem příslušné lokální proměnné podprogramu je pak ovšem vždy string [255].
Význam rezervovaného slova string v deklaracích formálních parametrů lze řídit direktivou {$P} kompilátoru. Ve stavu {$P–} je typem formálního parametru string [255] (jako ve starších verzích Turbo Pascalu), kdežto ve stavu {$P+} je typem formálního parametru otevřený řetězec — rezervované slovo string má pak v deklaracích formálních parametrů stejný význam jako identifikátor OpenString.
Direktiva {$P} je globální — uvádí se na začátku zdrojového textu (nepozději za hlavičkou) a platí v celém jeho rozsahu.
Sčítání řetězců Pokud jsou S1, S2 hodnoty řetězcových (nebo s řetězci kompatibilních) typů, pak výraz S1 + S2 má hodnotu typu string, vzniklou připojením platných znaků řetězce S2 za poslední platný znak řetězce S1. Délka výsledného řetězce je vypočtena jako součet délek řetězců S1 a S2 a oříznuta na maximální délku 255 znaků.
Relační operace Pro řetězce je definováno lexikografické uspořádání. Relační operace (mají obvyklé operátory <, >, =, <=, >= a <>) porovnávají v operandech znaky na stejných pozicích jako hodnoty typu Char (podle jejich ordinálních čísel). Chybějící znak je menší než kterýkoliv platný znak, prázdný řetězec je tedy nejmenší ze všech řetězců. Každý z operandů smí být libovolného s řetězci kompatibilního typu.
Standardní řetězcové podprogramy Pro práci s proměnnými a hodnotami řetězcových typů jsou dále implementovány následující standardní funkce a procedury.
function Concat (S1 [, S2...]: string): string;
Vrací řetězcovou hodnotu, získanou součtem hodnot všech (jednoho nebo více) svých parametrů. Pokud je délka takto získaného řetězce větší než 255, je automaticky zkrácena odříznutím přebytečných znaků zprava (od konce).
function Copy (Zdroj: string; Od, Pocet: Integer): string;
Vrací část řetězce Zdroj o délce Pocet znaků, počínaje znakem na pozici Od. Pro Od větší než aktuální délka řetězce nebo Pocet menší než jedna je vrácen prázdný řetězec. Případná záporná nebo nulová hodnota parametru Od je nahrazena jedničkou. Pokud Pocet specifikuje více znaků, než zbývá do konce řetězce, je vrácen pouze zbývající počet znaků.
function Length (S: string): Integer;
Vrací aktuální délku řetězce S.
function Pos (Hledej, Zdroj: string): Byte;
Vyhledá v řetězci Zdroj první výskyt „podřetězce“ Hledej. Pokud je podřetězec nalezen, vrací funkce pozici jeho prvního znaku v řetězci Zdroj, jinak vrací nulu.
procedure Delete (var Zdroj: OpenString; Od, Pocet: Integer);
Z řetězcové proměnné Zdroj „vymaže“ Pocet znaků, počínaje znakem na pozici Od. Pro zápornou nebo nulovou hodnotu parametru Od je vymazáno Pocet + Od – 1 znaků od začátku řetězce. Pro Od větší než aktuální délka Zdroj nebo Pocet menší než jedna není vymazán žádný znak. Pokud zbývá do konce řetězce Zdroj méně znaků než požadovaný počet, jsou vymazány pouze znaky zbývající.
procedure Insert (Vloz: string; var Cil: OpenString; Od: Integer);
Vypočte řetězec vzniklý vřazením řetězce Vloz do řetězce Cil na pozici Od. Po případném oříznutí je výsledek vrácen v parametru Cil. Pro Od < 1 je Vloz vřazen na začátek, pro Od větší než aktuální délka Cil na konec řetězce Cil.
procedure Str (Cislo [: dmíst [: znaků]]: číselný; var Cil: OpenString);
Konvertuje číselnou hodnotu Cislo (libovolného číselného typu) s akceptováním případného formátu na řetězcovou naprosto stejně jako procedura Write při výpisu čísla do textového souboru. Výsledek konverze vrací v řetězcové proměnné Cil.
procedure Val (Zdroj: string; var Cislo: číselný; var Chyba: Integer);
Konvertuje řetězcovou hodnotu Zdroj na číselnou. Řetězec Zdroj smí obsahovat pouze libovolný počet úvodních mezer a (podle celočíselného resp. reálného typu skutečného parametru Cislo) syntakticky správný zápis celočíselného resp. reálného literálu s případným (těsně přisazeným) znaménkem. Po úspěšné konverzi je parametru Cislo přiřazena vypočtená hodnota a parametru Chyba nula. V případě neúspěšné konverze je parametru Cislo přiřazena nula a parametru Chyba pozice chybného znaku řetězce.
Ze syntaktického hlediska smí být skutečným parametrem Cislo proměnná kteréhokoliv číselného typu. Vhodné jsou však pouze proměnné typu LongInt a Real (resp. Extended za stavu {$N+}), neboť při použití proměnných ostatních číselných typů může dojít k chybě překročení rozsahu.
{======================================================================}
program Podil;
{======================================================================}
var A, B: LongInt; { dělenec, dělitel }
function CtiCislo (var L: LongInt): Boolean;
{---------------------------------------------------------------------}
{ Načte celé číslo v textovém tvaru, zkonvertuje jej na hodnotu typu }
{ LongInt do parametru L a v případě konverzní chyby vypíše hlášení. }
{ Vrací True při úspěšné konverzi, False při neúspěšné. }
var S : string; { vstupní řetězec }
Chyba : Integer; { chyba konverze }
begin { CtiCislo }
Readln(S); { načtení řetězce }
Val(S, L, Chyba); { konverze }
if Chyba <> 0 then { ošetření chyby }
Writeln('Na pozici ', Chyba,
' chyba v zápisu celého čísla!');
CtiCislo := Chyba = 0 { vracená hodnota }
end; { CtiCislo }
begin { program }
Writeln; { výpis titulku }
Writeln('Výpočet celočíselného podílu');
Writeln('----------------------------');
Writeln;
repeat { načtení dělence }
Write('dělenec: ')
until CtiCislo(A);
repeat { načtení dělitele }
repeat
Write('dělitel: ')
until CtiCislo(B);
if B = 0 then Writeln('Dělitelem nesmí být nula!')
until B <> 0;
Writeln(A, ' div ', B, ' = ', A div B); { výpis podílu }
Writeln
end. { program }
VIII.3. |
Typy záznam |
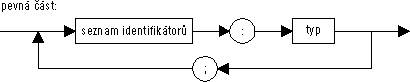
Obrázek 40: Popis typu záznam
|
V popisu záznamu je uveden seznam položek, obsahující buď jen pevnou část nebo jen variantní část nebo současně pevnou i variantní část, které jsou pak vzájemně odděleny středníkem. Ve všech třech případech smí být středník uveden i na konci seznamu.
V pevné části jsou uvedeny identifikátory a typy položek, které využívají paměťový prostor záznamu vždy stejným způsobem. Například v následujícím záznamu (obsahujícím pouze pevnou část) jsou vždy první a druhý byte interpretovány jako položky typu Byte a zbývající slovo jako položka typu Word.
Za rezervovaným slovem case, označujícím začátek variantní části, je uveden nepovinný identifikátor rozlišovací položky. Pokud tento identifikátor uveden je, stává se tato položka součástí pevné části — výskyt identifikátoru rozlišovací položky je překladačem chápán (pouze) jako deklarace této položky v pevné části. Typ rozlišovací položky musí být zato uveden vždy a musí být ordinální. Počet různých hodnot tohoto typu pak dovoluje předepsat ve variantní části až stejný počet variant — pro každou hodnotu zvláštní variantu. Hodnoty, uvozující a rozlišující větve jednotlivých variant, musí být uvedeny formou konstantních výrazů a musí být navzájem různé.record Den, Mesic : Byte; Rok : Word end
Varianty překrývají stejný paměťový prostor, jehož velikost je dána velikostí největší z nich. Veškeré položky všech variant jsou přístupné v každém okamžiku současně. Výběr varianty je dán výskytem identifikátoru položky, která je v ní obsažena.
type Znak = record
case Boolean of
False : (Symbol : Char);
True : (Kod : Byte)
end;
Například výše uvedenou deklarací je zaveden typ Znak jako záznam o velikosti 1 byte, který může být interpretován jako položka typu Char nebo Byte v závislosti na použití identifikátoru položky Symbol nebo Kod.
Variantních záznamů se užívá především za účelem úspory paměti. Například pro popis vybraných rovinných obrazců může být zaveden typ Obrazec, osahující souřadnice středu obrazce a druh obrazce — obdélník, pravidelný mnohoúhelník nebo kruh — a pro jednotlivé druhy obrazců pak další specifické položky: pro obdélník šířku a výšku, pro mnohoúhelník poloměr a počet vrcholů a pro kruh pouze poloměr. Pokud by všechny tyto údaje byly obsaženy v položkách pevné části záznamu, činila by jeho velikost 38 bytů:
type Obrazec = record
X, Y : Real; { 2 × 6 B }
Druh : (Obdelnik, Uhelnik, Kruh); { 1 B }
{ obdelnik: } Sirka, Vyska : Real; { 2 × 6 B }
{ uhelnik: } N : Byte; { 1 B }
RU : Real; { 6 B }
{ kruh: } RK : Real { 6 B }
end;
Nabízí se jednoduché vylepšení — nahradit položky RU a RK jedinou položkou R, neboť podle hodnoty položky Druh lze rozlišit, zda je R poloměrem mnohoúhelníka nebo kruhu. Variantní záznam využívá stejného principu, ale ve větším rozsahu — veškeré privátní položky obrazců jsou soustředěny v samostatných variantách, rozlišených hodnotou položky Druh:
type
Obrazec = record
X, Y : Real;
case Druh : (Obdelnik, Uhelnik, Kruh) of
Obdelnik : (Sirka, Vyska : Real);
Uhelnik : (N : Byte; RU : Real);
Kruh : (RK : Real)
end;
Velikost pevné části je pak 13 bytů, velikosti variant 12, 7 a 6 bytů, celková velikost záznamu tedy 25 (13 + 12) bytů. Dále je možno se všemi položkami pracovat současně, jako by byly deklarovány v pevné části záznamu: například použitím identifikátoru položky Sirka je zpřístupněna proměnná typu Real, zahrnující byty 13—18 záznamu (číslováno od nuly), kdežto použitím identifikátoru položky N je zpřístupněna proměnná typu Byte, alokovaná v bytu 13 záznamu. Ošetření kolizí mezi položkami z různých variant, ke kterým samozřejmě dojde při použití více než jedné varianty v jediné proměnné, je zcela věcí (autora) programu.
Typové konstanty V deklaraci typové konstanty, jejímž typem je záznam, je třeba uvést počáteční hodnotu konstanty ve tvaru konstantního záznamu. Jeho syntaktický diagram je uveden na obrázku 41.
Obrázek 41: Konstantní záznam

|
Položky konstantního záznamu jsou rozlišeny svými identifikátory, hodnotami jsou typové konstanty (odpovídajícího typu). Identifikátory musí být uvedeny ve stejném pořadí jako v deklaraci typu, nelze je vynechávat, nemusí však být uvedeny všechny. Obsahuje-li deklarace záznamu variantní část, smí konstantní záznam obsahovat definici hodnot položek pouze jedné z variant.
type Bod = record X, Y : Real end;
Usecka = array [0..1] of Bod;
Variant = record
A, B : Byte;
case C : Char of
'M' : (D, E : Byte);
'N' : (F, G : Byte)
end;
const B : Bod = (X : 0.0; Y : 0.0);
BB : Bod = (X : 0.0);
U : Usecka
= ((X : 10.0; Y : 20.0),
(X : 50.0; Y : 10.0));
V : Variant
= (A : 0.0; B : 0.0; C : 'M'; F : 0.0;
G : 0..0);
VV : Variant = (A : 0.0; B : 0.1);
Přístup k položkám Operace přístup k položce záznamu je definována pro proměnnou libovolného typu záznam tak, že uvedená proměnná je kvalifikována identifikátorem vybrané položky. Jako oddělovač proměnné a identifikátoru její položky slouží symbol tečka.
Obrázek 42: Přístup k položce záznamu
|
|
Výsledkem operace přístupu k položce záznamu je proměnná (!) typu vybrané položky záznamu. Přístup k položce záznamu proto lze uvést všude tam, kde je povolen výskyt proměnné typu položky.
const PocetZn = 15;
type Datum = record
Den, Mesic : Byte;
Rok : Word
end;
Student = record
Jmeno : string[30];
DatNar : Datum;
Znamky : array[1..PocetZn] of 1..5
end;
var S : Student;
| S.Jmeno | je proměnná typu string [30] | |
| S.DatNar | je proměnná typu Datum | |
| S.DatNar.Rok | je proměnná typu Word | |
| S.Znamky [7] | je proměnná typu 1 .. 5 | |
| S.Jmeno [20] | je proměnná typu Char |
Přiřazovací příkaz Je definován pro proměnné identických typů záznam. Jsou-li například D1 a D2 proměnné výše deklarovaného typu Datum, lze hodnotu proměnné D1 přiřadit proměnné D2 v zásadě dvěma způsoby — vcelku, přiřazovacím příkazem pro záznamy, nebo postupně, přiřazovacími příkazy pro jednotlivé položky záznamů:
D2 := D1; {vcelku }
D2.Den := D1.Den; {postupně}
D2.Mesic := D1.Mesic;
D2.Rok := D1.Rok
První způsob je úspornější co do rozsahu zápisu i rychlosti provedení.
Příkaz with Pro přístup k položce záznamu generuje překladač kód, zajišťující lokalizaci záznamu a jeho položky v operační paměti. Výsledná adresa položky je přitom udána relativně vůči počátku záznamu. Pokud z nějakého důvodu není adresa záznamu vyčíslitelná již v okamžiku překladu (je-li například příslušná proměnná typu záznam prvkem pole a uvedený index prvku není konstantním výrazem), je nutno její výpočet provádět až za běhu programu. Tento výpočet se pak provádí pro každý výskyt proměnné typu záznam znovu, což může běh programu výrazně zpomalit.
Při hromadného přístupu k položkám záznamu příkazem with se provádí výpočet adresy proměnné typu záznam pouze na jeho začátku a vypočtená adresa je uchována až do jeho ukončení. Uvnitř příkazu se pak místo přístupů k jednotlivým položkám proměnné uvádí již pouze identifikátory položek. Použití příkazu with je výhodné tam, kde se v relativně malém úseku zdrojového textu vyskytuje vícenásobně přístup k jedné nebo více položkám téže proměnné typu záznam.
Syntax hromadného přístupu k položkám proměnné typu záznam popisuje diagram na obrázku 43. Za rezervovaným slovem with se uvádí příslušná proměnná typu záznam a za rezervovaným slovem do dílčí příkaz, v němž se místo přístupů k položkám proměnné vyskytují již jen nekvalifikované identifikátory položek. Pokud má některý z nekvalifikovaných identifikátorů položek vně záznamu jiný význam, je tento vnější význam uvnitř příkazu with zastíněn (podobně je zastíněn nelokální význam lokálních identifikátorů uvnitř podprogramů).
Obrázek 43: Příkaz with

|
Je-li například D proměnná výše deklarovaného typu Datum, lze její hodnotu za použití hromadnéhu přístupu k položkám zobrazit takto:
Více dílčích příkazů lze do těla příkazu with zahrnout pomocí složeného příkazu. Například hodnotu 18. 1. 1959 lze proměnné D přiřadit takto:with D do Writeln (Den, '.', Mesic, '.', Rok)
Syntaxe příkazu with dovoluje i uvedení více než jediné proměnné typu záznam mezi rezervovanými slovy with a do. Přitom příkazwith D do begin Den := 18; Mesic := 1; Rok := 1959 end
je chápán jako příkazwith Z1, Z2 do příkaz
Uvnitř dílčího příkazu příkaz jsou v tomto případě přímo přístupné všechny položky proměnné Z2 a ty z položek proměnné Z1, které nejsou zastíněny položkami proměnné Z2. Nemá tedy smysl uvádět v příkaze with více proměnných stejného typu záznam.with Z1 do with Z2 do příkaz
{======================================================================}
program Klasifikace;
{======================================================================}
const MaxPocet = 40; { maximální počet studentů }
MaxDelka = 30; { maximální délka jmen }
type Student = record
Jmeno : string [MaxDelka]; { jméno studenta }
Znamka : Byte { jeho známka }
end;
Trida = array [1..MaxPocet] of Student; { pole záznamů }
{ všech studentů }
var T : Trida; { proměnná s daty studentů }
Pocet : 0..MaxPocet; { počet studentů }
Soucet : 0..5 * MaxPocet; { součet známek }
I, J, { pomocné proměnné }
Nejmensi : 0..MaxPocet;
Pom : Student;
begin { program }
Writeln; { tisk titulku }
Writeln('KLASIFIKACE');
Writeln;
Write('počet studentů : '); { specifikace počtu }
Readln(Pocet); { studentů }
Writeln;
Soucet := 0; { inicializace součtu }
for I := 1 to Pocet do { pro všechny studenty }
with T[I] do
begin
Write(I:2, '. jmeno : '); { načtení jména a známky }
Readln(Jmeno); { studenta }
Write(' znamka : ');
Readln(Znamka);
Inc(Soucet, Znamka) { aktualizace součtu }
end;
Writeln;
for I := 1 to Pocet - 1 do { pro prvního až předposl. }
begin { studenta }
Nejmensi := I; { nalezení indexu studenta }
for J := I + 1 to Pocet do { s nejmenším jménem ze }
if T[Nejmensi].Jmeno > T[J].Jmeno then { zbývajících }
Nejmensi := J;
if Nejmensi <> I then { zařazení na správné }
begin { místo }
Pom := T[I];
T[I] := T[Nejmensi];
T[Nejmensi] := Pom
end;
with T[I] do { tisk jména a známky }
Writeln(Jmeno, Znamka : 2+MaxDelka-Length(Jmeno))
end;
with T[Pocet] do { tisk jména a známky }
Writeln(Jmeno, { posledního studenta }
Znamka : 2+MaxDelka-Length(Jmeno));
Writeln;
Writeln('průměrný prospěch : ', { tisk průměrného }
Soucet/Pocet : 4 : 2); { prospěchu }
Writeln
end. { program }