XI. |
DYNAMICKÉ DATOVÉ STRUKTURY |
Použití izolovaných dynamických proměnných, z nichž každá je referována vlastní proměnnou příslušného ukazatelového typu, přináší výhody v takových aplikacích, které udržují v operační paměti velké množství dat. Všechny globální statické proměnné jsou totiž alokovány v jediném datovém segmentu, jehož maximální velikost je omezena na 64 KB. Podobně jsou všechny momentálně existující lokální proměnné alokovány na zásobníku programu, jehož velikost je opět omezena na 64 KB. Při problémech s velikostí paměťového prostoru v těchto segmentech programu lze některé rozsáhlé proměnné realizovat na heapu jako dynamické. Každý ze statických ukazatelů, použitých pro referenci (jakkoliv velkých) dynamických proměnných, totiž obsadí pouhé 4 byty.
Hlavní výhoda dynamických proměnných spočívá v možnosti jejich sdružování do rozsáhlých spojových struktur. Jednotlivé prvky spojové struktury (dynamické proměnné) musí obsahovat jednu či více (podle typu struktury) ukazatelových komponent pro realizaci odkazů na další prvky struktury. K manipulaci celé struktury pak postačí několik málo ukazatelových proměnných a její souhrnná velikost je omezena pouze kapacitou heapu.
XI.1. |
Spojové seznamy |
Deklarace struktury seznamu K implementaci spojového seznamu jsou potřebné dva datové typy — ukazatelový typ a typ jím referovaných prvků seznamu — které nazveme například Spoj a Prvek. Při deklaraci těchto typů ve zdrojovém textu programu ovšem dochází ke konfliktu se syntaxí jazyka, spočívajícím ve vzájemném pořadí deklarací. Typ Prvek totiž musí být uveden v popisu typu Spoj jako bázový typ ukazatele (Prvek by měl být deklarován dříve) a současně musí být typ Spoj uveden v popisu typu Prvek jako typ odkazu na následníka prvku (Spoj by měl být deklarován dříve). K odstranění tohoto rozporu povoluje syntax jazyka výjimku: v popisu libovolného ukazatelového typu smí být uveden dosud neznámý identifikátor bázového typu, který však musí být dodatečně deklarován nejpozději do konce deklarační části bloku, v němž je deklarován ukazatel:
type Spoj = ^Prvek; { typ ukazatele }
Prvek = record { typ prvku seznamu }
... { datové položky prvku }
Dalsi: Spoj { odkaz na následníka }
end; { prvku v seznamu }
var Zac : Spoj; { ukazatel na začátek seznamu }
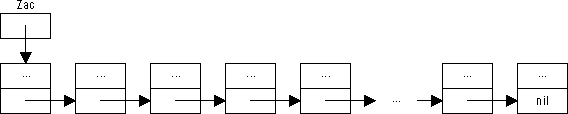
Z dynamických proměnných typu Prvek je pak možno vytvořit spojový seznam, schematicky znázorněný na obrázku.
Obrázek 49: Spojový seznam
|
|
Přístup k prvkům seznamu Přímo přístupným je ve spojovém seznamu jeho první prvek — za platnosti výše uvedených deklací má přístup k tomuto prvku tvar Zac^ (přístup k proměnné, referované typovým ukazatelem Zac). To je ovšem proměnná typu Prvek, mezi jejíž položky náleží i Zac^.Dalsi — proměnná typu Spoj. Hodnotou této proměnné je ukazatel na druhý prvek seznamu, takže přístup k druhému prvku seznamu lze realizovat zápisem Zac^.Dalsi^ a obdobně lze postupovat dále.
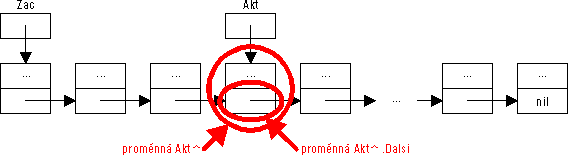
Pro prvky na vyšších pozicích v seznamu však tento způsob přístupu není schůdný, nehledě k tomu, že jej lze použít pouze pro prvky na pozicích známých již při psaní zdrojového textu. Nabízí se však jiné řešení, založené na použití pomocné proměnné typu Spoj, ve které bude uchováván ukazatel na aktuální (právě přístupný) prvek seznamu:
var Akt: Spoj;
Při práci se seznamem pak bude proměnná Akt využívána následovně:
Akt := Zac
Akt := Akt^.Dalsi
První z uvedených příkazů nastavuje pomocného ukazatele na začátek seznamu a druhý jej „posune“ o prvek vpřed. Potřebným počtem „posuvů“ (v nějakém cyklu) lze pomocného ukazatele nastavit na kterýkoliv prvek seznamu, který je pak přímo přístupný (zápisem Akt^).
Obrázek 50: Aktuální prvek seznamu
|
Průchod seznamem V případě, že hodnota položky Dalsi posledního prvku seznamu je udržována na nil, lze využitím výše uvedeného principu realizovat průchod seznamem — aplikovat zvolenou operaci na všechny prvky seznamu:
Akt := Zac;
while Akt <> nil do
begin
... { proveď operaci nad proměnnou Akt^ }
Akt := Akt^.Dalsi
end
Nejčastěji používanými spojovými seznamy jsou tzv. zásobníky, fronty a uspořádané seznamy. Liší se především způsobem rozšiřování (přidávání prvků) a zkracování (odebírání prvků).
XI.2. |
Zásobník |
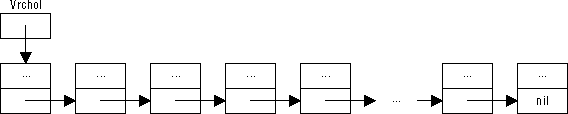
Pro referenci zásobníku postačuje jediný ukazatel — ukazatel na jeho vrchol. Poslední prvek v zásobníku je rozpoznán podle hodnoty položky Dalsi, která musí být udržována na nil. Pokud je zásobník prázdný, má hodnotu nil ukazatel na jeho vrchol.
type Spoj = ^Prvek; { typ ukazatele na prvek }
Prvek = record { typ prvku }
... { datové položky prvku }
Dalsi: Spoj { odkaz na další prvek }
end;
var Vrchol : Spoj; { ukazatel na vrchol zásobníku }
Obrázek 51: Zásobník
|
Inicializace zásobníku Inicializací je míněno založení prázdného zásobníku (neobsahujícího žádný prvek). K tomu je nutno pouze nastavit hodnotu proměnné Vrchol na nil.
procedure Inicializace;
{---------------------}
begin { Inicializace }
Vrchol := nil
end; { Inicializace }
Obrázek 52: Inicializace zásobníku
|
|
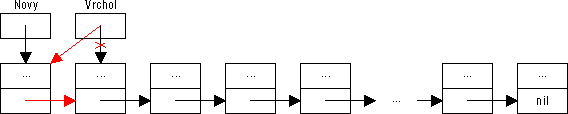
Vložení prvku Nový prvek se vkládá před prvek na vrcholu zásobníku. Uvedené proceduře je nový prvek zadán hodnotou ukazatele, který jej referuje.
procedure VlozPrvek (Novy: Spoj);
{-------------------------------}
begin { VlozPrvek }
Novy^.Dalsi := Vrchol;
Vrchol := Novy
end; { VlozPrvek }
Prvním příkazem je ukazatel na původně vrcholový prvek (resp. nil, pokud je zásobník prázdný) vložen do položky Dalsi nového prvku, čímž je původní řetěz prvků zásobníku připojen za nový prvek. Druhým příkazem je aktualizován ukazatel na vrchol zásobníku — rozšířený řetěz prvků je připojen k proměnné Vrchol.
Obrázek 53: Vložení prvku na vrchol zásobníku
|
Odebrání prvku Odebírá (odstraňuje) se prvek na vrcholu zásobníku. Ten musí být nejprve vyřazen ze struktury seznamu a poté uvolněn z heapu. Operace odebrání prvku musí brát v úvahu možnost, že zásobník je prázdný (není co odebrat).
procedure OdeberPrvek;
{--------------------}
var Odebrany: Spoj;
begin { OdeberPrvek }
if Vrchol <> nil then
begin
Odebrany := Vrchol;
Vrchol := Vrchol^.Dalsi;
Dispose (Odebrany)
end
end; { OdeberPrvek }
Původní hodnota proměnné Vrchol, tj. ukazatel na vrchol zásobníku a současně na odebíraný prvek, je po uložení do pomocné proměnné nahrazena ukazatelem na následníka odebíraného prvku (resp. hodnotou nil, pokud je odebíraný prvek poslední). Odebraný prvek je pak uvolněn z heapu.
Obrázek 54: Odebrání prvku z vrcholu zásobníku

|
{======================================================================}
program Rak;
{======================================================================}
type Spoj = ^Prvek; { typ ukazatele na prvek }
Prvek = record { typ prvku zásobníku }
Znak : Char;
Dalsi : Spoj
end;
var Vrchol, Pom : Spoj; { vrchol zás. a pomocný ukazatel }
Vstup, Vystup : Text; { vstupní a výstupní soubor }
Jmeno : string; { specifikace souboru }
begin { program }
Writeln; { tisk titulku }
Writeln('RAK');
Writeln;
Write('vstupní soubor : '); { inicializace vstupního souboru }
Readln(Jmeno);
Assign(Vstup, Jmeno);
Reset(Vstup);
Write('výstupní soubor : '); { inicializace výstupního souboru }
Readln(Jmeno);
Assign(Vystup, Jmeno);
Rewrite(Vystup);
Vrchol := nil; { inicializace zásobníku }
while not EOF(Vstup) do { cyklus zpracování řádek }
begin
while not EOLn(Vstup) do { cyklus načtení znaků řádky do }
begin { zásobníku ze souboru Vstup }
New(Pom); { založení nového prvku }
with Pom^ do
begin
Read(Vstup, Znak); { načtení znaku do položky Znak }
Dalsi := Vrchol { vložení prvku na vrchol }
end; { zásobníku }
Vrchol := Pom { aktualizace vrcholu zásobníku }
end; { další znak }
Readln(Vstup); { přesun na další řádku vstupu }
while Vrchol <> nil do { cyklus výpisu znaků řádky ze }
begin { zásobníku do souboru Vystup }
Write(Vrchol^.Znak); { výpis znaku }
Pom := Vrchol; { uvolnění prvku na vrcholu }
Vrchol := Vrchol^.Dalsi; { zásobníku }
Dispose(Pom)
end; { další znak }
Writeln(Vystup) { odřádkování v souboru Vystup }
end; { další řádka }
Close(Vstup); { zavření souborů }
Close(Vystup)
end. { program }
XI.3. |
Fronta |
type Spoj = ^Prvek; { typ ukazatele na prvek }
Prvek = record { typ prvku }
... { datové položky prvku }
Dalsi: Spoj { odkaz na další prvek }
end;
var Zac, { ukazatele na začátek }
Kon : Spoj; { a konec fronty }
Prvek na začátku fronty a prvek na konci fronty musí být trvale referovány ukazatelovými proměnnými (zde Zac a Kon). Pokud je fronta prázdná, mají obě tyto proměnné hodnotu nil. Hodnota ukazatele na následníka posledního prvku fronty nemá žádné použití, proto ji lze ponechat nedefinovanou.
Obrázek 55: Fronta
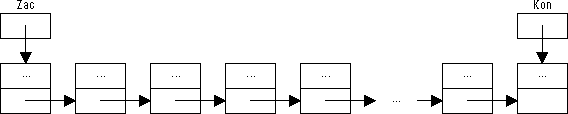
|
Inicializace fronty Inicializací je míněno založení prázdné fronty (neobsahující žádný prvek). K tomu je nutno pouze nastavit hodnoty proměnných Zac a Kon na nil.
procedure Inicializace;
{---------------------}
begin { Inicializace }
Zac := nil;
Kon := nil
end; { Inicializace }
Obrázek 56: Inicializace fronty
|
|
Vložení prvku Pokud je fronta prázdná, vkládá se nový prvek na její začátek, jinak na konec (za poslední prvek). Uvedené proceduře je nový prvek zadán hodnotou ukazatele, který jej referuje.
procedure VlozPrvek (Novy: Spoj);
{-------------------------------}
begin { VlozPrvek }
if Zac = nil then Zac := Novy
else Kon^.Dalsi := Novy;
Kon := Novy
end; { VlozPrvek }
Prvním (podmíněným) příkazem je nový prvek připojen buď přímo k proměnné Zac (pokud je fronta prázdná) nebo za poslední prvek. Druhým příkazem je aktualizována hodnota ukazatele na konec fronty.
Obrázek 57: Vložení prvku na konec fronty
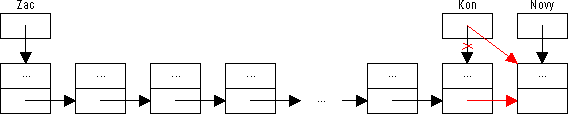
|
Odebrání prvku z fronty Pokud je fronta prázdná (Zac = nil), není odebrán žádný prvek. Jediný obsažený prvek (Zac = Kon) je uvolněn z heapu a fronta je reinicializována jako prázdná. Při více prvcích je z fronty vyřazen a z heapu uvolněn prvek první.
procedure OdeberPrvek;
{--------------------}
var Odebrany: Spoj;
begin { OdeberPrvek }
if Zac <> nil then
if Zac = Kon then begin
Dispose (Zac);
Zac := nil;
Kon := nil
end
else begin
Odebrany := Zac;
Zac := Zac^.Dalsi;
Dispose (Odebrany)
end
end; { OdeberPrvek }
Je-li odebíraný prvek ve frontě jediný, může být uvolněn přímo, jinak je postup stejný jako při odebírání prvku ze zásobníku (v případě zásobníku i fronty je totiž prvek odebírán ze začátku seznamu).
Obrázek 58: Odebrání prvku ze začátku fronty

|
{======================================================================}
program Odchylky;
{======================================================================}
type Spoj = ^Prvek; { typ ukazatele na prvek }
Prvek = record { typ prvku fronty }
Cislo : Real;
Dalsi : Spoj
end;
var Zac, Kon, { začátek a konec fronty }
Pom : Spoj; { pomocný ukazatel }
Pocet, I : LongInt; { počet čísel, pomocná proměnná }
Soucet, Prumer : Real; { součet a aritmetický průměr }
begin { program }
Writeln; { tisk titulku }
Writeln('ODCHYLKY');
Writeln;
New(Kon); { inicializace fronty }
Zac := Kon; { s jedním prvkem }
with Kon^ do
begin
Read(Cislo); { načtení prvního čísla }
Soucet := Cislo { inicializace součtu čísel }
end;
Pocet := 1; { inicializace počtu čísel }
while not SeekEOF do { cyklus čtení dalších čísel }
begin
with Kon^ do
begin
New(Dalsi); { nový prvek za posledním }
Kon := Dalsi { aktualizace konce fronty }
end;
with Kon^ do
begin
Read(Cislo); { načtení čísla }
Soucet := Soucet + Cislo { aktualizace součtu }
end;
Inc(Pocet) { aktualizace počtu }
end; { další číslo }
Prumer := Soucet/Pocet; { výpočet aritm. průměru }
for I := 1 to Pocet do { pro všechny prvky fronty }
begin
Pom := Zac; { označení prvního prvku }
with Pom^ do
begin
Writeln(Cislo, '':10, Cislo-Prumer); { tisk čísla a odchylky }
Zac := Dalsi { aktualizace začátku fronty }
end;
Dispose(Pom) { uvolnění označeného prvku }
end { další prvek }
end. { program }
XI.4. |
Uspořádaný seznam |
type Spoj = ^Prvek; { typ ukazatele na prvek }
Prvek = record { typ prvku }
... { datové položky prvku }
Klic : Word; { klíč pořadí prvku }
Dalsi : Spoj { odkaz na další prvek }
end;
var Zac { ukazatele na začátek }
Nar : Spoj; { a nárazník seznamu }
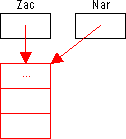
Klíčem pro uspořádání takto implementovaného seznamu bude položka Klic jeho prvků. To v zásadě může být kterákoliv z datových položek prvků. Typem klíčové položky by však měl být některý z typů, pro jehož hodnoty je jazykem definováno uspořádání (zde je použit typ Word), jinak je nutno implementovat vlastní relační operace. Ukazateli Zac a Nar budou trvale referovány první prvek a nárazník seznamu.
Obrázek 59: Seznam s nárazníkem
|
Inicializace Spočívá ve vytvoření nárazníku (na hodnotách jeho položek nezáleží, takže mohou zůstat nedefinované) a přiřazení jeho adresy proměnným Zac a Nar.
procedure Inicializace;
{---------------------}
begin { Inicializace }
New (Nar);
Zac := Nar
end; { Inicializace }
Obrázek 60: Inicializace seznamu s nárazníkem
|
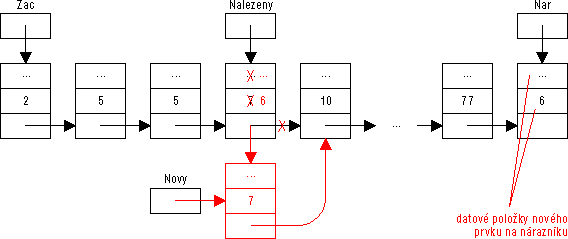
Vložení prvku Nechť je vytvářen seznam uspořádaný například nesestupně podle hodnoty položky Klic jeho prvků a nechť jsou hodnoty datových položek, z nichž má být vytvořen nový prvek obsaženy v datových položkách nárazníku (proměnné Nar^).
procedure VlozPrvek;
{------------------}
var Nalezeny, Novy: Spoj;
begin { VlozPrvek }
Nalezeny := Zac;
while Nalezeny^.Klic < Nar^.Klic do
Nalezeny := Nalezeny^.Dalsi;
if Nalezeny = Nar then begin
New (Nar^.Dalsi);
Nar := Nar^.Dalsi
end
else begin
New (Novy);
Novy^ := Nalezeny^;
Nalezeny^ := Nar^;
Nalezeny^.Dalsi := Novy
end
end; { VlozPrvek }
Procedurou VlozPrvek je nejprve nalezen první prvek od začátku seznamu, jehož položka Klic nemá hodnotu menší než položka Klic vkládaného prvku (na nárazníku). Pokud je nalezeným prvkem nárazník (Nalezeny = Nar), je vkládaný prvek největší a patří tudíž na konec seznamu — je mu ponechána dynamická proměnná nárazníku a nárazník je vytvořen nový. V opačném případě (Nalezeny <> Nar) patří vkládaný prvek před prvek nalezený. Pak musí být uplatněn poměrně komplikovaný postup: založit nový prvek, hodnotu nalezeného do něj zkopírovat, do nalezeného zkopírovat hodnotu nárazníku (s datovými položkami nového prvku) a vřadit nový prvek za prvek nalezený. K prostému vřazení nového prvku před prvek nalezený by totiž musel být nejprve nalezen předchůdce nalezeného prvku v seznamu.
Obrázek 61: Vložení prvku před označený prvek
|
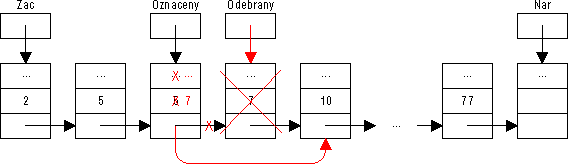
Odebrání prvku Ze seznamu je odebírán prvek na obecné pozici, označený nějakým ukazatelem. Uvedené proceduře je tento ukazatel předán jako parametr.
procedure OdeberPrvek (Oznaceny: Spoj);
{-------------------------------------}
var Odebrany: Spoj;
begin { OdeberPrvek }
if Oznaceny <> Nar then
begin
Odebrany := Oznaceny^.Dalsi;
if Odebrany = Nar then Nar := Oznaceny
else Oznaceny^ := Odebrany^;
Dispose (Odebrany)
end
end; { OdeberPrvek }
Pokud je označeným prvkem nárazník, požadavek na jeho odebrání je ignorován (nárazník být odebrán nesmí). V ostatních případech (Oznaceny <> Nar) nebude označený prvek odebrán přímo, neboť by bylo nutné nalézt jeho předchůdce v seznamu. Místo toho bude později z heapu uvolněn až následník označeného prvku v seznamu, jehož adresa je proto uložena do pomocné proměnné Odebrany. Pokud bude takto uvolněn nárazník seznamu (Odebrany = Nar), čili pokud je označeným prvek poslední platný prvek před nárazníkem, je z označeného prvku učiněn nový nárazník, jinak je do označeného prvku zkopírována hodnota jeho uvolňovaného následníka. Posledním příkazem je pak následník označeného prvku konečně uvolněn.
Obrázek 62: Odebrání označeného prvku
|
{======================================================================}
program CetnostSlov;
{======================================================================}
const MaxDelkaSlova = 30;
SlovniZnaky : set of Char { znaky, povolené uvnitř slov }
= ['A'..'Z', 'Á', 'Č', 'Ď', 'É', 'Ě', 'Í', 'Ň',
'Ó', 'Ř', 'Š', 'Ť', 'Ú', 'Ů', 'Ý', 'Ž'];
type Spoj = ^Prvek; { typ ukazatele }
Prvek = record { typ prvku seznamu }
Slovo : string [MaxDelkaSlova];
Cetnost : Word;
Dalsi : Spoj
end;
var Zac, { ukazatel na začátek seznamu }
Nar, { ukazatel na nárazník seznamu }
Aktualni : Sipka; { pomocný ukazatel }
Soubor : Text; { vstupní soubor a po jeho }
{ zpracování výstupní soubor }
Jmeno : string; { systémová specifikace souboru }
function PrectenoSlovo: Boolean; { Pokusí se o přečtení dalšího }
{------------------------------} { slova ze souboru do nárazníku }
{ seznamu. V případě úspěchu vrací True. Pokud zbytek souboru tvoří }
{ již jen oddělovače slov, vrací False. }
var Znak: Char; { čtený znak }
begin { PrectenoSlovo }
repeat { "přeskočení" oddělovačů }
Read(Soubor, Znak)
until (Znak in SlovniZnaky) or EOF(Soubor);
if Znak in SlovniZnaky then { byl přečten slovní znak }
begin
PrectenoSlovo := True; { čtení slova bude úspěšné }
with Nar^ do
begin
Slovo := ''; { inicializace slova }
repeat
Slovo := Slovo + Znak { připojení znaku k slovu }
Read(Soubor, Znak) { přečtení dalšího znaku }
until not (Znak in SlovniZnaky);
end
end
else { přečteny pouze oddělovače }
PrectenoSlovo := False { v souboru již nebylo slovo }
end; { PrectenoSlovo }
procedure ZaradSlovo; { Pokud je slovo, umístěné }
{-------------------} { v nárazníku, již obsaženo }
{ v seznamu, aktualizuje četnost jeho výskytu. Pokud ne, zařadí jej }
{ na odpovídající pozici a nastaví četnost jeho výskytu na 1. }
var Aktualni, { vyhledávací ukazatel }
Novy : Spoj; { ukazatel na nový prvek }
begin { ZaradSlovo }
Aktualni := Zac; { od začátku seznamu }
while Aktualni^.Slovo < Nar^.Slovo { vyhledání prvního slova, }
do Aktualni := Aktualni^.Dalsi; { které není abecedně menší než }
{ zařazované }
if Aktualni = Nar then { zařazované slovo v seznamu }
with Nar^ do { nebylo nalezeno a je největší }
begin { - je mu ponechán nárazník }
Cetnost := 1; { nastavena četnost jeho výskytu}
New(Dalsi); { vytvořen nový nárazník a }
Nar := Dalsi { aktualizován ukazatel na něj }
end
else if Aktualni^.Slovo = Nar^.Slovo then { slovo nalezeno - }
Inc(Aktualni^.Cetnost) { aktualizována jeho četnost }
else { nalezeno větší slovo }
begin
New(Novy); { vytvoření nového prvku }
Novy^ := Aktualni^; { překopírování nalezeného prvku}
with Aktualni^ do { zařazení vkládaného slova }
begin
Slovo := Nar^.Slovo;
Cetnost := 1;
Dalsi := Novy
end
end
end; { ZaradSlovo }
begin { program }
Writeln; { tisk titulku }
Writeln('PROGRAM ČETNOST SLOV');
Writeln;
Write('vstupní soubor : '); { inicializace vstup. souboru }
Readln(Jmeno);
Assign(Soubor, Jmeno);
Reset(Soubor);
New(Nar); { inicializace seznamu }
Zac := Nar;
while not SeekEof(Soubor) do { cyklus čtení slov }
if PrectenoSlovo then ZaradSlovo { zpracování přečteného slova }
Close(Soubor); { zavření vstupního souboru }
Write('výstupní soubor : '); { inicializace výst. souboru }
Readln(Jmeno);
Assign(Soubor, Jmeno);
Rewrite(Soubor);
Writeln(Soubor, 'SLOVO', { záhlaví tabulky četnosti slov }
'ČETNOST':MaxDelkaSlova+10);
Writeln(Soubor);
Aktualni := Zac; { cyklus zpracování prvků }
while Aktualni <> Nar do { seznamu }
begin
with Aktualni^ do { výpis slova a jeho četnosti }
Writeln(Soubor, Slovo,
Cetnost:MaxDelkaSlova+10-Length(Slovo));
Aktualni := Aktualni^.Dalsi; { přesun ukaz. na další prvek }
Dispose(Zac); { uvolnění zpracovaného prvku }
Zac := Aktualni { aktualizace začátku seznamu }
end;
Dispose(Nar); { uvolnění nárazníku }
Close(Soubor) { zavření výstupního souboru }
end. { program }
XI.5. |
Spojové stromy |
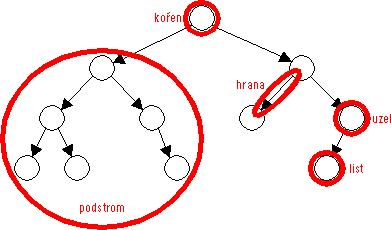
Obrázek 63: Strom
|
Budiž U zvolený uzel stromu a H jedna z něj vystupujících hran. Všechny uzly stromu, do nichž existuje cesta obsahující hranu H, tvoří podstrom uzlu U. Operace nad stromem jsou často realizovány rekurzivními algoritmy, které využívají shodnost struktury podstromu a celého stromu — na podstrom lze pohlížet jako na samostatný (menší) strom. Uzel, jehož všechny vystupující hrany mají hodnotu nil, se nazývá list stromu. Všechny podstromy listu jsou prázdné (neobsahují žádný uzel).
Deklarace struktury stromu Prakticky se budeme zabývat pouze binárními stromy, z jejichž uzlů vystupují dvojice hran. Uzly budou reprezentovány dynamickými proměnnými stejného typu záznam, obsahujícími právě dvě ukazatelové položky na dva podstromy uzlu. Pokud bude nutno podstromy uzlu vzájemně odlišit, budeme používat termíny levý podstrom uzlu a pravý podstrom uzlu.
type Hrana = ^Uzel; { typ hran stromu }
Uzel = record { typ uzlů stromu }
... { datové položky uzlu }
Levy, { ukazatele na levý }
Pravy : Hrana { a pravý podstrom }
end;
var Koren : Hrana; { ukazatel na kořen stromu }
Celý strom tedy bude v programu referován jediným ukazatelem — ukazatelem na kořen stromu, který bude hodnotou proměnné Koren. Schéma binárního stromu, vyhovujícího uvedeným deklaracím, je uvedeno na následujícím obrázku. Nespecifikované datové položky uzlů jsou reprezentovány trojtečkami, výchozí body hran odpovídají ukazatelovým položkám Levy a Pravy uzlů. Hrany, jejichž hodnotou je nil, jsou zobrazeny jako tečky.
Obrázek 64: Binární strom
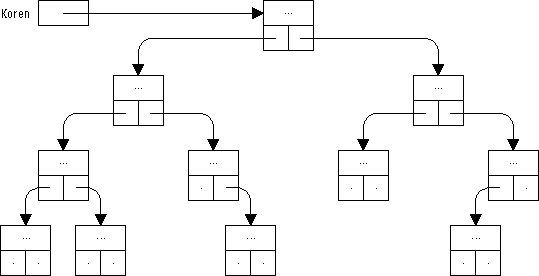
|
Průchod binárním stromem Při potřebě uskutečnit nějakou operaci nad všemi uzly stromu je prováděn průchod stromem. Pokud je strom binární, lze průchod uskutečnit některou ze tří rekurzivních metod. Metody se liší vzájemným pořadím provedení operace nad aktuálním uzlem a průchodu jeho podstromy. Metoda preorder vykoná operaci nad každým uzlem před průchodem oběma jeho podstromy, metoda inorder mezi průchodem jedním a druhým podstromem uzlu a metoda postorder až po průchodu oběma podstromy uzlu.
Programová realizace každé z uvedených metod bude mít tvar rekurzivní procedury či funkce, jejímž parametrem bude (kromě případných dalších) ukazatel na zpracovávaný uzel. Například:
procedure Preorder (H: Hrana);
{----------------------------}
begin { Preorder }
if H <> nil then
begin
... { operace nad uzlem H^ }
Preorder (H^.Levy); { průchod levým podstromem }
Preorder (H^.Pravy) { průchod pravým podstromem }
end
end; { Preorder }
procedure Inorder (H: Hrana);
{---------------------------}
begin { Inorder }
if H <> nil then
begin
Inorder (H^.Levy); { průchod levým podstromem }
... { operace nad uzlem H^ }
Inorder (H^.Pravy) { průchod pravým podstromem }
end
end; { Inorder }
procedure Postorder (H: Hrana);
{-----------------------------}
begin { Postorder }
if H <> nil then
begin
Postorder (H^.Levy); { průchod levým podstromem }
Postorder (H^.Pravy); { průchod pravým podstromem }
... { operace nad uzlem H^ }
end
end; { Postorder }
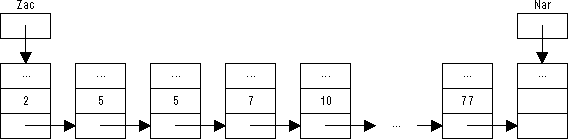
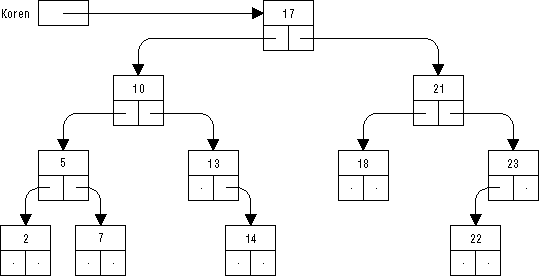
Například při průchodu binárního stromu na obrázku 65 (níže) budou podle zvolené metody zpracovány číselné položky uzlů v tomto pořadí:
preorder: 17, 10, 5, 2, 7, 13, 14, 21, 18, 23, 22 inorder: 2, 5, 7, 10, 13, 14, 17, 18, 21, 22, 23 postorder: 2, 7, 5, 14, 13, 10, 18, 22, 23, 21, 17
Uspořádaný strom Nejčastěji jsou binární stromy aplikovány v třídicích a vyhledávacích algoritmech. Uzly jsou pak ve stromu uspořádány podle hodnot jedné ze svých datových položek — klíče. Uspořádání uzlů ve stromu může být definováno například tak, že klíč každého uzlu je větší než klíče všech uzlů jeho levého podstromu a menší než klíče všech uzlů jeho pravého podstromu.
Obrázek 65: Uspořádaný binární strom
|
Časová složitost vyhledávání je při reprezentaci dat binárním stromem úměrná pouze výšce stromu, nikoli počtu jeho uzlů. Výška stromu je počet hran, které obsahuje cesta z kořene stromu do nejvzdálenějšího listu. Pokud je strom vyvážený, tj. pokud se počty uzlů v podstromech každého uzlu stromu liší nejvýše o jeden, je jeho výška rovna pouze celé části log2 n, kde n je celkový počet uzlů stromu. Zvláště výrazný je rozdíl mezi velmi velkým počtem uzlů a jeho logaritmem: log2 n << n.
{======================================================================}
program Trideni;
{======================================================================}
type Hrana = ^Uzel;
Uzel = record
Cislo : Real; { zařazené číslo }
Mensi, Vetsi : Hrana { ukazatele na levý a pravý }
end; { podstrom uzlu }
var Koren : Hrana; { ukazatel na kořen stromu }
C : Real; { načtené číslo }
procedure Zarad (C: Real; var Podstrom: Hrana); { zařadí číslo C do }
{---------------------------------------------} { podstromu, jehož }
{ kořen je referován proměnnou Podstrom, rekurzivní aplikací pravidla:}
{ - je-li podstrom prázdný,vytvoří jeho kořen a do něj vloží číslo C }
{ - není-li prázdný a C je menší než položka Cislo kořene podstromu, }
{ zařadí C do levého podstromu kořene }
{ - není-li prádný a C je větší nebo rovno položce Cislo kořene }
{ podstromu, zařadí C do pravého podstromu kořene }
begin { Zarad }
if Podstrom = nil then { prázdný podstrom - žádný uzel }
begin
New(Podstrom); { vytvoření kořene }
with Podstrom^ do
begin
Cislo := C; { vložení čísla }
Mensi := nil; { žádné další uzly }
Vetsi := nil
end
end
else { neprázdný podstrom - uzel }
with Podstrom^ do { Podstom^ již existuje }
if C < Cislo then Zarad(C, Mensi) { zařaď do levého podstromu }
else Zarad(C, Vetsi) { zařaď do pravého podstromu }
end; { Zarad }
procedure Tisk (Podstrom: Hrana); { vytiskne hodnoty všech čísel, }
{-------------------------------} { obsažených v uzlech podstromu }
{ a uvolní jim odpovídající dynamické proměnné z heapu }
{ - pro tisk čísel je nutno použít průchod podstromu metodou inorder: }
{ nejdřív menší čísla, pak aktuální, nakonec větší čísla }
{ - pro uvolňování uzlů je nutno volit průchod metodou postorder: }
{ uvolnit nejprve všechny uzly v obou podstromech aktuálního uzlu, }
{ než je uvolněn on sám }
begin { Tisk }
if Podstrom <> nil then { je-li podstrom neprázdný }
begin
with Podstrom^ do
begin
Tisk(Mensi); { nejprve levý podstrom }
Writeln(Cislo); { potom tisk čísla v akt. uzlu }
Tisk(Vetsi) { potom pravý podstrom }
end;
Dispose(Podstrom); { nakonec uvolnění aktuálního }
end { uzlu }
end; { Tisk }
begin { program }
Koren := nil; { inicializace prázdného stromu }
while not SeekEOF do { cyklus čtení a zařazování }
begin { čísel }
Read(C); { načti číslo }
Zarad(C, Koren) { zařaď jej do stromu }
end; { další číslo }
Tisk(Koren) { tisk čísel a uvolnění stromu }
end. { program }
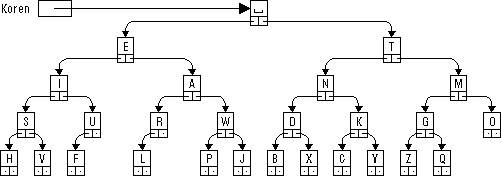
Obrázek 66: Dekódovací strom programu Morse
|
Dekódování vstupu provádí procedura Dekoduj. Pro jednoduchost se předpokládá, že všechny kódy písmen (dílčí posloupnosti teček a čárek) na vstupu jsou platné a jsou ukončeny alespoň jedním oddělovačem. Dekódování celého vstupního textu probíhá jako cyklus. Před jeho zahájením, tj. před načtením prvního znaku, je nastaven pomocný ukazatel Smer na kořen stromu. V každém průchodu cyklem se pak přečte jeden znak kódu a podle jeho hodnoty (tečka, čárka nebo oddělovač) se buď provede přesun ukazatele Smer na levý podstrom aktuálního uzlu (tečka) nebo přesun ukazatele Smer na pravý podstrom aktuálního uzlu (čárka) nebo vytištění písmene v aktuálním uzlu a přesun ukazatele Smer zpět do kořene stromu (oddělovač). Například po zpracování kódu .-.. (vlevo, vpravo, vlevo, vlevo) bude vytištěno písmeno L.
{======================================================================}
program Morse;
{======================================================================}
type Sipka = ^Uzel;
Uzel = record
Znak : Char;
Tecka, Carka : Sipka
end;
var Koren : Sipka;
function VytvorUzel (Z: Char; T, C: Sipka): Sipka; { vytvoří uzel, }
{------------------------------------------------} { jeho položkám }
{ přiřadí hodnoty parametrů Z, T a C a vrací ukazatel na něj }
var P: Sipka;
begin { VytvorUzel }
New(P);
with P^ do
begin
Znak := Z;
Tecka := T;
Carka := C
end;
VytvorUzel := P
end; { VytvorUzel }
procedure Dekoduj; {čte, dekóduje a vypisuje text zprávy }
{----------------}
var Smer : Sipka;
Symbol : Char;
begin { Dekoduj }
Smer := Koren; { inicializace }
while not Eof do { dekódovací cyklus }
begin
Read(Symbol);
case Symbol of
'.' : Smer := Smer^.Tecka; { tečka: přechod na levý podstrom }
'-' : Smer := Smer^.Carka { čárka: přechod na pravý podstrom }
else begin { oddělovač: }
Write(Smer^.Znak); { tisk písmene z aktuálního uzlu }
Smer := Koren { začátek kódu dalšího písmene }
end
end
end;
Writeln
end; { Dekoduj }
begin { program }
Koren := VytvorUzel(' ', { tento příkaz vytvoří }
VytvorUzel('E', { dekódovací strom }
VytvorUzel('I', { a ukazatele na jeho }
VytvorUzel('S', { kořen předá proměnné }
VytvorUzel('H', nil, nil), { Koren }
VytvorUzel('V', nil, nil)),
VytvorUzel('U',
VytvorUzel('F', nil, nil),
nil)),
VytvorUzel('A',
VytvorUzel('R',
VytvorUzel('L', nil, nil),
nil),
VytvorUzel('W',
VytvorUzel('P', nil, nil),
VytvorUzel('J', nil, nil)))),
VytvorUzel('T',
VytvorUzel('N',
VytvorUzel('D',
VytvorUzel('B', nil, nil),
VytvorUzel('X', nil, nil)),
VytvorUzel('K',
VytvorUzel('C', nil, nil),
VytvorUzel('Y', nil, nil))),
VytvorUzel('M',
VytvorUzel('G',
VytvorUzel('Z', nil, nil),
VytvorUzel('Q', nil, nil)),
VytvorUzel('O', nil, nil))));
Dekoduj { čtení, dekódování }
end. { program } { a výpis zprávy }
| příklad vstupu: | .--./.-./---/--./.-./.-/--//--/---/.-./..././ |
|
| odpovídající výstup: | PROGRAM MORSE |